Discovering a new database: Neo4J
| | 7 minutes | 1377 words
{kind=link}
2018 is here. Happy new year !
2017 was a productive year in every direction. Workwise , it was a blast. I joined an amazing team and we are doing very nice things all together.
But my brain is constantly sparkling and I’ve got plenty of new ideas. During the last months, I’ve explored new universes. Symfony, NodeJS, Opendata, Telegram bot API, Twitter API… I’ve learned so much things in a so short time, it’s crazy how much behind we can be if we do not have side projects to let our creativity express itself. It’s now my job to try to push these new technologies and new tools at work, that is the most complicated part.
Lately, I’ve been playing a lot with Opendata, NodeJS, Wikidata, iRail… As you may know, iRail provides Belgian railway (open)data and I was looking for a way to get trains stations and their lines. I ended up doing irail-api a NodeJS/NPM package and a custom tool in NodeJS based on it, using Leaflet and Websockets. That tool helped me to complete the Belgium station data on Wikidata. There are more than 600 stations, and I completed them last week. All the details of this in the Github issue.
Thanks to all of this, it’s now possible to retrieve, for each Belgian station, its associated train lines and its adjacent stations.
It’s a lot of data, a lot of contributions and there is no way to visualize properly the result, yet.
In order to test if I could use those data in a practical way, I built a small script that returns the list of stations that I would pass if I want to go from Station A to Station B. A BFS algorithm is used to find the path in between the two stations.
Then a reply of this tweet from Christophe “ikwattro” Willemsen, a twitter friend of mine, lit the spark.
you should try @neo4j m8!
— Christophe Willemsen (@ikwattro) December 30, 2017
To be honest, I was curious because of its tweets and dedication to Neo4J since I know him but I never had the opportunity or the need to use it… until now.
Neo4J is a graph database management system developed by Neo4j, Inc. Described by its developers as an ACID-compliant transactional database with native graph storage and processing, Neo4j is the most popular graph database according to DB-Engines ranking. It is available in a GPL3-licensed open-source “community edition” Neo4j is implemented in Java and accessible from software written in other languages using the Cypher Query Language through a transactional HTTP endpoint, or through the binary “bolt” protocol. (source)
Graphs, or Graphs theory, far from being a recent data handling development is actually nearly 300 years old and can be traced to Leonhard Euler, a Swiss mathematician. Euler was looking to solve an old riddle known as the Seven Bridges of Königsberg. Set on the Pregel River, the city of Königsberg included two large islands connected to each other and the mainland by seven bridges. The challenge was to map a route through the city that would cross each bridge only once while ending at the starting point. Euler realized that by reducing the problem to its basics, eliminating all features except landmasses and the bridges connecting them, he could develop a mathematical structure that proved the riddle impossible.
Today’s graphs are based entirely from Euler’s design – with land masses now referred to as a “node” (or “vertex”), while the bridges are the “links” (also known as “relationships” or “edges”). One thing that’s great about graph databases however is that their end users don’t need to know anything about graph theory in order to experience immediate practical benefits. (source)
So, I downloaded the Neo4J community edition and I played with it. I did the tutorial that are provided by the installer and I was impressed, that the least I can say.
How did I never tried this before ?!
To learn it, I wanted to use the Belgian railway data, so, the first thing I did was to find a way to build and import all the data from iRail and Wikidata into Neo4J. The file I’m using is available on Gist, you can play with it if you want.
Then, once this file has been imported in Neo4J, I was able to query the database using CQL, the Cypher query language, a query language invented by and for Neo4J.
Hereunder you will find the description of the queries, the CQL query and the result in Neo4J.
Oh and by the way, Big thanks to Christophe “ikwattro” Willemsen for its help for unblocking me with some queries!
Queries
To get the list of all the stations and lines in the database:
MATCH p=()-->()
RETURN p

The list of all the stations and lines in the database
To get the list of stations attached to ‘Line 96’ or ‘Line 97’:
MATCH (station:Station)-[relationship:PART_OF]->(line:Line)
WHERE line.name IN ['Line 96 (Infrabel)', 'Line 97 (Infrabel)']
RETURN station, relationship, line
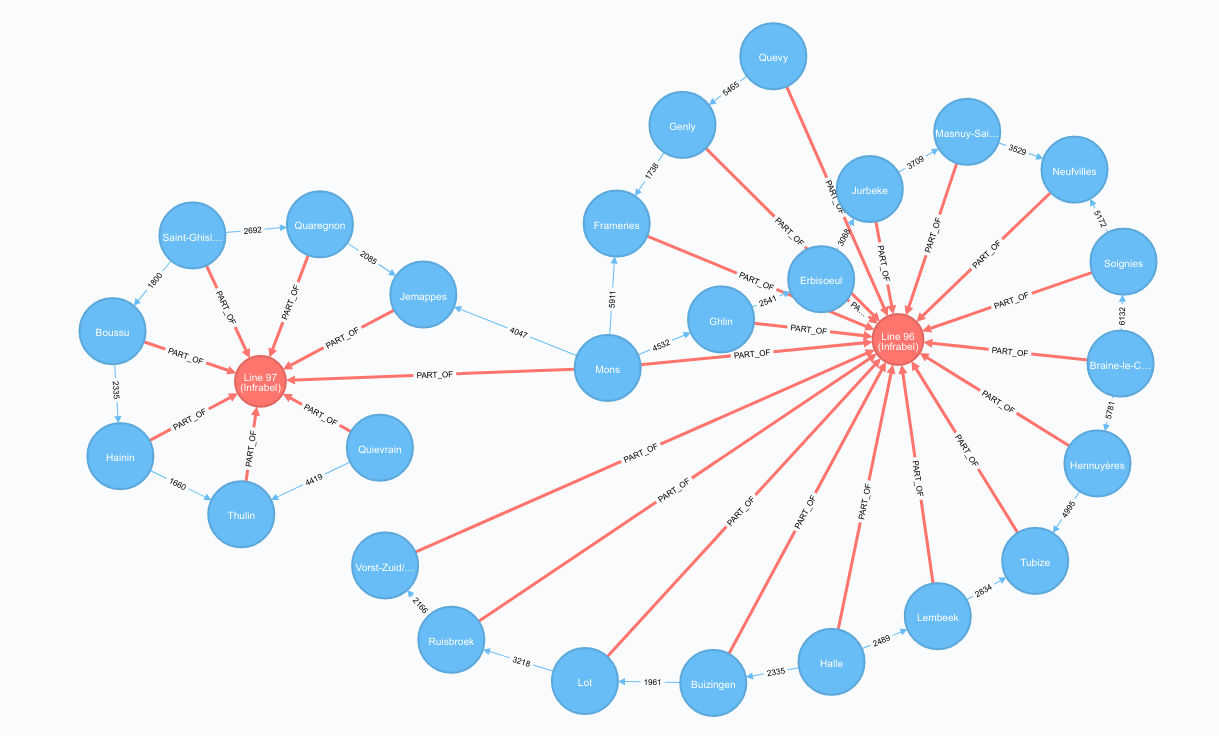
The list of stations attached to Line 96 or Line 97
To get the shortest path “in nodes” from Quaregnon to Brussels-South:
MATCH (s1:Station {name: 'Quaregnon'}), (s2:Station {name: 'Brussels-South/Brussels-Midi'}), path = allShortestPaths((s1)-[:ADJACENT_OF*]-(s2))
WITH path, nodes(path) AS stations
MATCH (s1:Station)-[p1:PART_OF]-(l:Line)-[p2:PART_OF]-(s2:Station) WHERE s1 IN stations AND s2 IN stations
RETURN stations, relationships(path), p1, p2, l

The shortest path in nodes from Quaregnon to Brussels-South
In Neo4J, the edges(or relationships) in between nodes are first class citizen and may have properties just like
nodes. In this case, the relationship ADJACENT_OF has a property distance. The distance in between each station is
displayed as relationship label and you may notice that the distance between Braine-Le-Comte and Halle is not the
shortest. The is a path passing through more station but shorter.
“let’s use a graph “to see” that… that’s a purpose of a graph databases anyway !
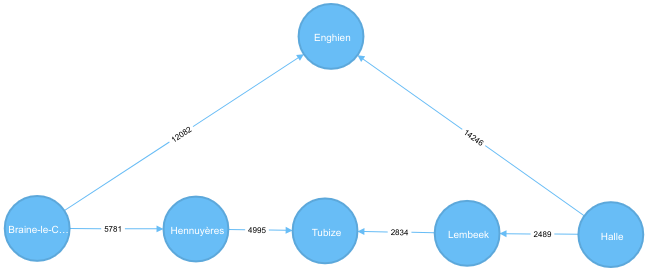
Paths between Braine-le-Comte and Halle
On this graph, we can clearly notice that there is a better solution, a shorter path in terms of distance, than what Neo4J is giving me. It’s not a mistake actually.
The function
allShortestPaths() will
always return paths with the least nodes. But in our case, we have to take in account the distance property attached
in relationships and find the path with the smallest distance, no matter how much nodes there are in the path.
The solution is to use another algorithm: Dijkstra.
To get the shortest path “in distance” from Quaregnon to Brussels-South:
MATCH (from:Station{name:'Quaregnon'}), (to:Station{name:'Brussels-South/Brussels-Midi'})
CALL apoc.algo.dijkstra(from, to, 'ADJACENT_OF', 'distance')
YIELD path AS path, weight AS weight
WITH path, nodes(path) AS stations
MATCH (s1:Station)-[p1:PART_OF]-(l:Line)-[p2:PART_OF]-(s2:Station) WHERE s1 IN stations AND s2 IN stations
RETURN stations, relationships(path), p1, p2, l

The shortest path in distance from Quaregnon to Brussels-South
To get the list of all stations with only one adjacent station:
MATCH (:Station)-[relationships:ADJACENT_OF]-(station:Station)
WITH station, count(relationships) as rels
WHERE rels = 1
RETURN station

The list of all stations with only one adjacent station
Conclusion
In addition to being beautiful, these graphs make it possible to interpret an amount of data that generally are hard to grasp while they are just tables and rows in a database.
If I wanted to do that with a regular relational database, it would have been impossible to have such a result without a huge amount of data preprocessing.
Imagine what we could do if we had an ultra complete Belgian railway dataset… we could probably do things in a better way…
And if you start to think deeper about it, you will see that graphs are everywhere in your everyday life. They are a vital part of our online lives, powering everything from social media sites to the retail recommendations on e-shops, online dating sites… and so much more.
I really think that I will start to use it more and more,
I guess overall interest in the graphs will continue to grow. The real-time nature of a graph database makes it an excellent platform for unlocking business value from data relationships, which simply can’t be carried out on traditional SQL or most NoSQL databases. The uses and applications for graph databases seem endless, and it’s exciting to consider what innovations they will continue to power as the world unlocks the value of data relationships. (source)